B-Tree Indexing Basics Explained 🗃️

A database’s performance largely relies on it’s response to queries. There are primarily two functionalities of a database, to store data and when queried later, it should effectively present the data stored. In order to efficiently find the data one is looking for, we need a data structure, known as indexes.
📍What are Database Indexes?
In simple terms, index is a pointer to data in a table. The pointer helps the storage engines to locate data with a reduced latency. Any kind of index usually slows down writes, because the index also needs to be updated every time data is inserted. Therefore, it is an important trade-off in storage systems to identify the required indexes for a dataset.
There are various data structures that can work as indexes such as Bitcask, SSTables, LSM-trees etc. In this article, I will convey the basic understanding of B-trees as an indexing data structure. It is the most widely used indexing structure for database management systems.
Disk Index
Data is ultimately stored in physical disks. Any block on the disk can be accessed via the sector and the track number. In a more granular sense, a byte on a particular block can be located with the sector, track and the offset value.
Let’s take a very basic example to understand how a table is stored on a disk. For a block size of 512 bytes and a row size of 128 bytes, a total of (512/128), 4 rows can be stored in a block. Now, to store 100 rows, a total of 25 blocks on the disk will be utilized.
In a simple scenario, to look for a particular key in the database, the engine needs to access at most 25 blocks. In order to reduce this time, indexes are introduced. As defined earlier, an index is a pointer to data, therefore, we shall create another table, where each row will have the key and pointer to every value in the database. Considering the size of each row of the index table to be 16 bytes, it would take at most 4 disk blocks.

Now, to lookup for a particular row, the database engine first needs to locate the key value in the index table (4 blocks) and then directly read the record (1 block) from the Data Table using the pointer value. This drastically reduces the access time from 25 blocks to (4+1) 5 blocks. The access time reduction comes with a tradeoff as every time a new key is inserted, the index table also needs to be updated.
Multi Level Indexing
With an increase in the number of records (let’s say 1000 rows), accessing the index table itself will require more disk blocks to be read. To further reduce this time, another level of indexing can be done. Another level of index can be created that stores the pointer to each block of the first-level index table.
In this example, we have created another index table which stores the block address (ID 1 to 32 and so on) of the keys from the first index table.

Since the multi-level index table requires only 2 blocks to get accessed, now the record can be accessed in (2 + 1 + 1) 4 block reads for a 1000 rows data table.
This is the basic idea of how indexing works. As the scale of the dataset increases, more levels of indexing can be added. The diagram below explains how the intuition of self-managed indexing trees is introduced.

📍What are B Trees?
A B-tree is a data structure that provides sorted data and allows searches, sequential access, attachments and removals in sorted order. The B-tree is highly capable of storing systems that write large blocks of data. The B-tree simplifies the binary search tree by allowing nodes with more than two children.
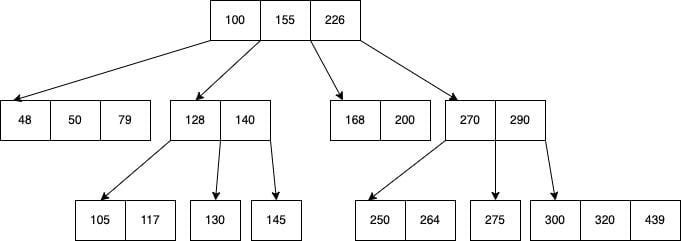
It is a search tree where the pointer to the left of a parent value holds child nodes smaller than the parent, whereas the pointer to the right of the parent node holds values greater than that of the parent node value. Inserting/Deleting any value in this tree will be performed while ensuring the search property of the tree remains consistent. They are self-balancing, meaning all leaf nodes (nodes at the bottom level) are at the same depth, ensuring efficient search across the entire structure.
B+ tree is an extension of the B tree. The difference in B+ tree and B tree is that in B tree the keys and records can be stored as internal as well as leaf nodes whereas in B+ trees, the records are stored as leaf nodes and the keys are stored only in internal nodes. The leaf nodes are also linearly connected in B+ trees to improve range-query performance.

📍How B+ Indexing Works?
Let’s assume a table with multilevel indexing using B+ trees.
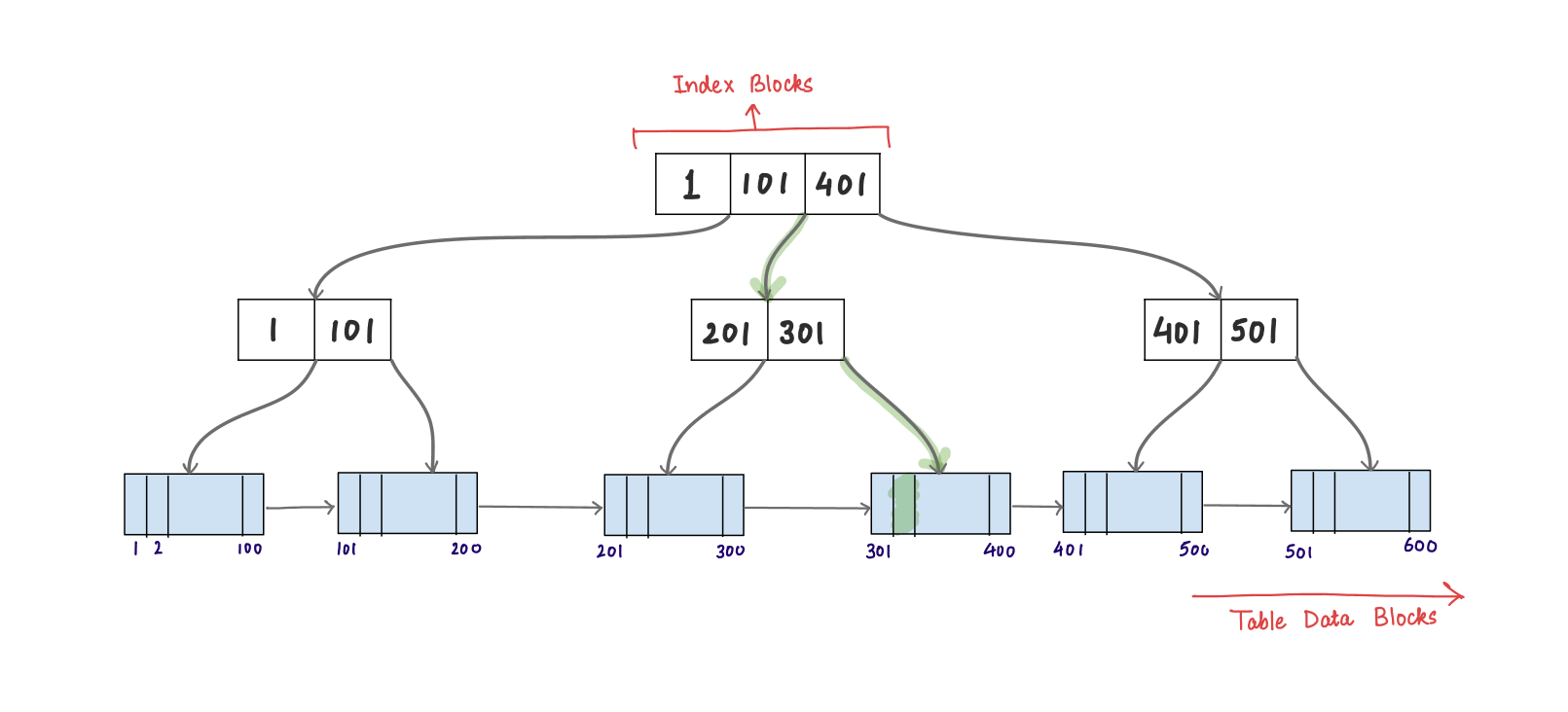
Now in-order to search for a key, example “302", the search traversal flows from the root index to the final data blocks as depicted in the diagram with green highlight. The complete search process was completed with the traversal of 3 disk blocks.
📍Conclusion
Wrapping up, B-trees are very ingrained in the architecture of databases and provide consistently good performance for many workloads by reducing the disk block access time multi-fold. Databases should be able to store, read, and alter data in an efficient manner. The B-tree structure makes it easy to insert and read data. In actual Database implementation, the database stores data using both B-tree and B+tree.
While the inclusion of B+ index improves the reading time of a database query, the drawbacks cannot be ignored. Creating and maintaining a B-Tree requires additional storage space compared to storing un-indexed data. Moreover, Inserting or updating data in a B-Tree can be slower than doing the same in un-indexed data because the tree structure needs to be maintained to ensure balance.
Therefore, database engineers must consider the tradeoff between the read and write performance and devise a suitable index for their tables.
